
There is an interesting kind of lock-in forming.
For years, software companies have tried to keep us inside their systems by making the workflow easier once we are in there. The new version is subtler. Use our harness and the economics are better. Use our app, our memory, our project space, our hosted workflow, and the whole thing feels cheaper, faster, and more convenient.
So what do you do?
You use the harness.
That is not irrational. It is exactly what the incentives are designed to make you do.
The next lock-in is not only the model. It is the context you allow the harness to own.
Three kinds of value
When we talk about AI systems, we usually talk about model power.
How good is GPT? How good is Claude? How good is the next model? How long is the context window? How strong is the reasoning? How cheap are the tokens?
That matters.
But model power is only one layer of value.
The second layer is the information in your own head. Your judgement. Your taste. Your experience. The way you work. The people you know. The scar tissue from all the projects that looked simple until the third meeting.
Most of that has never been written down properly. Some of it should not be. But it is valuable.
The third layer is your context.
Not one document. Not one memory file. Not a neat little folder called "context" with everything politely arranged by someone with infinite patience.
Your context is the living root system underneath your work.
The root system under the work
Imagine a tree.
On the surface is you, doing the work. Underneath is the root system that makes the work possible.
One root goes into your job. Then it splits into the projects you are working on. Each project splits again into documents, decisions, conversations, plans, unresolved risks, useful people, awkward constraints, and the things everyone sort of knows but nobody has written down.
Another root goes into home. Another into friends. Another into finances. Another into health. Another into the small but important facts that make life run.
Then the work root splits across systems.
Email. Slack. Notion. Google Drive. SharePoint. Word documents. Local files. SaaS systems. Finance tools. CRM. ERP. Project boards. Random PDFs. That spreadsheet with the real answer in it. The old document that is wrong but still gets copied into new work every six months.
If you have ever opened an unmanaged Google Drive or SharePoint and seen "final", "final-final", and "final-27-really-final", you know the problem.
The information is there.
The truth is not always obvious.
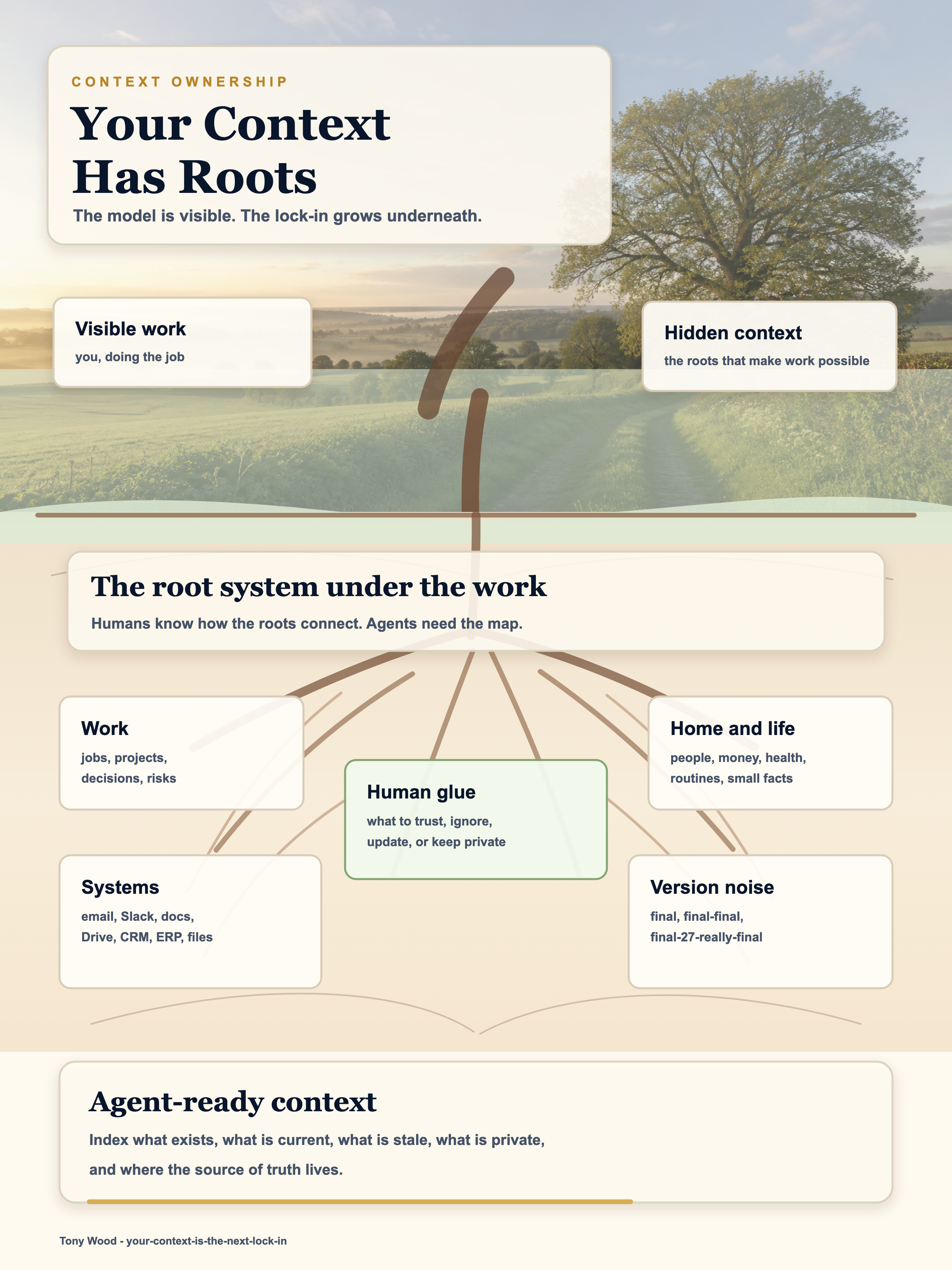
Humans are the glue
At the moment, humans do a lot of the integration work.
We know which file to ignore. We remember that the meeting changed the plan. We know that the old budget was politically useful but operationally dead. We know which Slack thread mattered, which email was noise, and which folder looks authoritative but should be treated with suspicion.
That glue is not glamorous. It is not usually in the job description. But it is a large part of how organisations actually function.
If we want agents to work well, we have to decide how that glue gets represented.
Not perfectly. Not all at once. But enough that an agent can understand what is current, what matters, what can be ignored, and where the useful source of truth probably lives.
Context needs a home
One of the big tasks now is deciding how to pull that context together into a meaningful store.
That does not have to mean a grand platform. In many cases, starting with simple files is better.
Markdown is a perfectly good way to store clear text. JSON is useful when the structure matters. XML still exists, whether we like it or not. A database is useful when speed, consistency, querying, permissions, and scale start to matter.
The right format depends on the job.
If slow is acceptable, plain text may be enough. If fast lookup matters, you need an index. If many people or systems are writing into it, you probably need stronger structure. If permissions matter, and they usually do, you need to design for that from the beginning.
A folder of Markdown with a good index is not "just files" anymore.
Operationally, it is a database.
The index matters
The archive is not the clever bit.
The clever bit is knowing what is recent, what is authoritative, what has been superseded, and what is safe to use.
We are not naturally good at maintaining that by hand. Look at most desktops. Look at most downloads folders. Look at shared drives that have been through three restructures and two enthusiastic productivity initiatives.
People make folders because they are trying to remember where they put things. Then they make more folders because the first set stopped making sense. Almost nobody keeps a clean spreadsheet of every file, what it means, whether it is current, who owns it, and what should use it.
It takes too much time.
But agents change the economics of that work. They can help extract, summarise, classify, compare, and keep an index warm. They can help turn a mess of material into something navigable.
The question is whether that navigable layer belongs to you, or to the product surface you happened to use first.
Some systems still earn their place
This is not an argument to cancel every SaaS subscription and live in a heroic pile of text files.
Some systems add real value, especially in teams.
CRMs are useful because teams need shared customer process. Finance systems are useful because teams need controls, audit trails, approvals, and a common understanding of money. Operational systems can be useful because they coordinate work between people.
Team context is different from personal context. We have not fully worked out that boundary yet.
But the question is becoming sharper:
Which systems are providing real team value, and which ones are mostly acting as a harness around your own information?
Once you can bring useful context to Claude, Codex, ChatGPT, or whatever comes next, some old software categories start to look different.
Not useless.
Different.
Start small
The practical step is not to design the perfect second brain for your entire life by Friday.
Start with one project.
Pick something you actually do. Pull together the live documents, the decision log, the useful contacts, the open questions, the old versions that should not be trusted, and the current source of truth.
Write down what an agent would need to know to help you without constantly asking the same basic questions.
Then add an index.
What exists? What is current? What is stale? What is private? What is safe to share? What is the preferred source? What should be ignored unless a human explicitly asks for it?
That is the beginning of a context store.
It will not be perfect. Good. Perfect systems have a habit of never arriving.
But a small, useful context store is enough to teach you what the bigger one needs to become.
The ownership question
The coming fight is not just who has the best model.
It is who owns the working context around the model.
If your context lives only inside one vendor's harness, then the harness becomes the place where your work is easiest to do. That is convenient. It is also a form of dependency.
If you own enough of your context, in a form that can move, be indexed, and be given to different agents, then you have more choice.
You can still use the harness.
You just do not have to become the harness.
That is the thing to start thinking about now.
Where is your context? Who can read it? Who can move it? Who can index it? Who can tell what is current?
Answer those questions for one project, then another.
Start small and work up.