
I have been thinking about LLM firewalls, tool gates, prompt injection, and all the modern language around keeping agentic systems under control.
And the more I look at it, the more I think: Stoicism is quite cool, actually.
Not in the motivational-poster sense. Not in the "be emotionless" sense, which is usually a bad reading of it. I mean the practical operating idea underneath it: notice the impression, test the judgement, then choose the action.
That is a very old human idea. It is also a very good design pattern for AI.
The model has an impression
When an agentic system is working well, the model is constantly forming impressions.
This looks like a useful file. This email probably means X. This user may want Y. This command should fix the issue. This data might need to be sent here. This response sounds right.
Some of those impressions are useful. Some are wrong. Some are persuasive but unsafe. Some are technically valid and operationally stupid, which is a particular kind of modern joy.
The mistake is letting every impression become an action.
That is where the Stoic bit matters. A thought is not a command. A feeling is not a policy. A confident model answer is not authority.
The model may propose. The system must decide.
An LLM firewall is really a discipline layer
The phrase "LLM firewall" sounds like a product category. It may become one. But the idea underneath it is more basic and more useful.
An LLM firewall is not just a clever classifier that tries to spot bad prompts. That helps, but it is not enough. The stronger version is a runtime discipline layer around the model and its tools.
It asks questions before anything meaningful happens:
- What context is the model allowed to see?
- What tools is it allowed to call?
- What data is it allowed to move?
- What destinations are allowed?
- What needs human approval?
- What must be logged?
- What must never happen automatically?
That is not glamorous. It is not the bit people demo on a stage. But it is the bit that stops a bright idea from becoming an expensive mistake.
Control what can actually be controlled
One of the most useful Stoic ideas is to separate what is inside your control from what is not.
In AI, that distinction is practical.
You cannot fully control what a large language model will think in every possible context. You can improve it. You can instruct it. You can test it. You can make it better behaved. But if the system is powerful enough to reason across messy language, it will sometimes surprise you.
What you can control much more reliably is the world around it.
You can control tool permissions. You can control file access. You can control whether it can write, send, post, push, buy, delete, deploy, email, or call an external API.
You can control schemas. You can control allowed domains. You can label data as public, internal, confidential, or private. You can require approval before irreversible actions. You can sandbox code. You can block network egress. You can record what happened.
That is where deterministic code is strongest. Not in trying to understand language better than the model, but in deciding what the model is allowed to cause.
Do not give every thought a credit card
This is the bit I think people miss with agentic AI.
If you are just chatting to a model, the failure mode is usually a bad answer. That can still matter, but it is mostly contained.
Once the model has tools, the failure mode changes. Now a bad answer can become a file write, a database update, an email, a deployment, a calendar invite, a payment, a public post, or a private data leak.
At that point, the question is no longer "can the model sound sensible?"
The question is: "what is this system allowed to do when it sounds sensible?"
That is why the best agentic systems need a pause between thought and action.
Give the model room to think. Let it explore. Let it propose. Let it explain the route. Let it challenge you if it believes something is wrong.
But do not give every thought a credit card, a shell, an email account, and a production database.
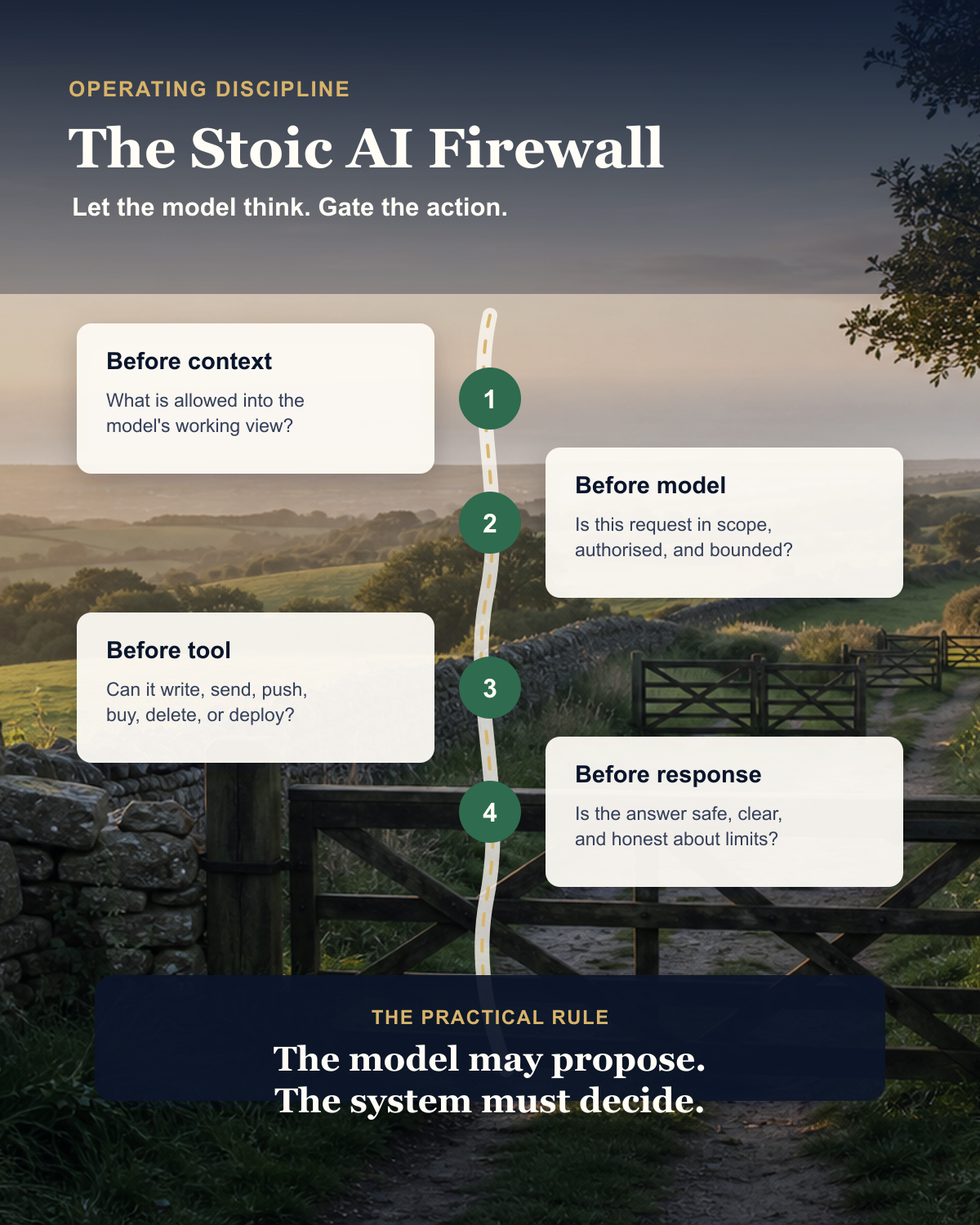
The four useful pauses
The LLM-firewall research I have been looking at keeps coming back to four useful control points.
The first pause is before context. What information is allowed into the model's working view? Is this public context, private context, client context, or mixed context? Are we accidentally giving the model two things together that should never meet?
The second pause is before the model call. Is the request in scope? Is the user allowed to ask for this? Is the system about to create a situation where the model has too much authority for the task?
The third pause is before tool use. This is the big one. Is the tool allowed? Are the arguments valid? Is the destination allowed? Is sensitive data leaving? Is this reversible? Does a human need to approve it?
The fourth pause is before the response. Is the answer exposing private information? Is it claiming authority it does not have? Is it leaking prompts, reasoning, secrets, or hidden context? Is it clear about uncertainty?
That is a very practical discipline.
Impression. Judgement. Action. Account.
Stoic agents would be more useful
A Stoic agent is not passive. It is not timid. It does not refuse everything because refusal looks safer on a dashboard.
A Stoic agent is useful because it can distinguish between thinking and acting.
It can say: this seems right, but I do not have authority to do it.
It can say: this action is possible, but the destination is wrong.
It can say: I can draft the email, but I should not send it.
It can say: I can inspect the logs, but I need approval before changing production.
It can say: the user sounds confident, but the data says this crosses a stop-line.
That is not weakness. That is discipline.
This is the Spine part
There is the generic security version of this idea, which is the LLM firewall: a runtime layer that controls context, tools, data movement, approvals, logs, and side effects.
But in my Head / Heart / Gut / Spine model, I would describe this more simply.
This is Spine.
Head asks whether the system understands enough to act. Heart asks what this will do to people, trust, dignity, and relationship. Gut listens for pressure, anomaly, fear, mismatch, and the sense that something is off before the proof has arrived.
Spine asks a different question: are we actually allowed to do this?
That is what the firewall is doing when it is working properly. It is not trying to be the whole judgement system. It is not replacing evidence, care, or instinct. It is the part that turns authority into behaviour.
Can the agent see this context? Can it use this tool? Can it send this data to that destination? Can it write to this system? Is this reversible? Does this need a human? Is this a stop-line?
Those are Spine questions.
So, yes, we can talk about LLM firewalls, tool brokers, schemas, egress controls, approval gates, and audit logs. We need that language.
But underneath it, the operating pattern is simpler:
Head, Heart, and Gut advise. Spine decides whether action is allowed.
The practical lesson
I think this is where the next generation of agentic systems gets interesting.
We do not need agents that are merely obedient. We do not need agents that are frightened of action. We need agents that can think fluently and act under control.
That means the model is not the whole system. The model is one part of the system. Around it we need permissions, policies, gates, logs, approvals, sandboxes, data labels, and judgement routes. In HHGS terms, we need Spine strong enough to hold the action boundary while the rest of the system thinks.
That sounds technical, but the underlying idea is very human.
Not every thought deserves to become an action.
Stoicism knew that. Good agentic systems should know it too.