Abstract
Long-running agentic systems do not need more memory by default. They need better judgement about what deserves attention, what should be remembered, and what should alter the system's posture.
This paper proposes a practical trigger language for agentic systems. Words such as fear, surprise, pain, shame, curiosity, distrust, pressure, and confusion should not be treated as claims that machines have human emotions. They are compact labels for control-relevant telemetry. They help route attention, constrain behaviour, create reviewable memory, and preserve human supervision without logging everything.
The core claim is simple: the useful question is not whether agents can feel fear or surprise. The useful question is whether we can name operational signals in human language, route them consistently, and learn from them without storing every scrap of noise.
Keywords: agentic AI; triggers; long-running agents; SNAXK; exception-driven memory; signal language; fear; pain; pressure; confusion; provenance; Web Annotation; CloudEvents; observability; incident management.
Reader Guide
What to look for
- Attention: triggers are not emotions; they are named signals that decide what deserves attention.
- Control: signals should change posture, routing, constraints, or review when they matter.
- Memory: the point is exception-driven learning, not logging every operational scrap.
- Judgement: triggers feed Head, Heart, Gut, and Spine; they do not decide by themselves.
Executive Summary
Agentic systems are beginning to run for longer periods, handle more context, work across tools, and act on behalf of people and organisations. This creates a new problem. If every event, message, tool call, and intermediate state is treated as equally meaningful, the agent becomes a hoarder. If too little is retained, the agent cannot learn from exceptions, near misses, or repeated mistakes.
Triggers offer a middle path. A trigger is a named operational signal that says: this event may deserve attention, routing, constraint, memory, or review.
The trigger model developed across Tony Wood's public writing and SNAXK research has five working principles:
- Store exceptions, not noise.
- Use human-readable signal names over machine-readable routing metadata.
- Keep signals advisory until a judgement layer interprets them.
- Separate pre-harm warnings from active incident pressure.
- Make memory reviewable, source-linked, and bounded.
In practice, a long-running agent should not simply "remember everything". It should ask:
- Did this surprise us?
- Did this reveal a gap in our own standard?
- Did this create curiosity worth bounded exploration?
- Did this reduce trust in a source, route, or counterpart?
- Is there pre-harm fear?
- Is there active pain?
- Is pressure distorting judgement?
- Is the context too confused to act safely?
- Is a communication, governance, or consequence threshold being crossed?
The answer should not automatically cause action. A signal is an input into judgement. The runtime shape is:
- Detect signal pressure quickly.
- Interpret it through Head, Heart, and Gut.
- Let Spine decide whether to proceed, constrain, verify, refuse, limp, stop, or escalate.
- Record the signal only when it changes routing, memory, review, or future behaviour.
1. The Problem: Agents That Hoard, Drift, or Miss the Point
Long-running agents produce and encounter an enormous amount of operational exhaust. Tool outputs, chat messages, status updates, retries, decisions, corrections, failed assumptions, and environment changes can all be written down. But more data does not equal more knowledge.
In "Don't Build a Hoarder-Build a Learner", the core argument is that agentic memory should be exception-driven. Humans do not remember every commute or routine meeting. We remember the moments where reality diverged from expectation, where something mattered, where an error exposed a deeper pattern, or where a future action should change.
The same principle applies to agents. An agent that remembers everything becomes expensive, noisy, and harder to supervise. An agent that remembers nothing repeats avoidable mistakes. The design problem is to decide what counts.
Triggers are one answer. They give the system a compact way to say: this is not just another event.
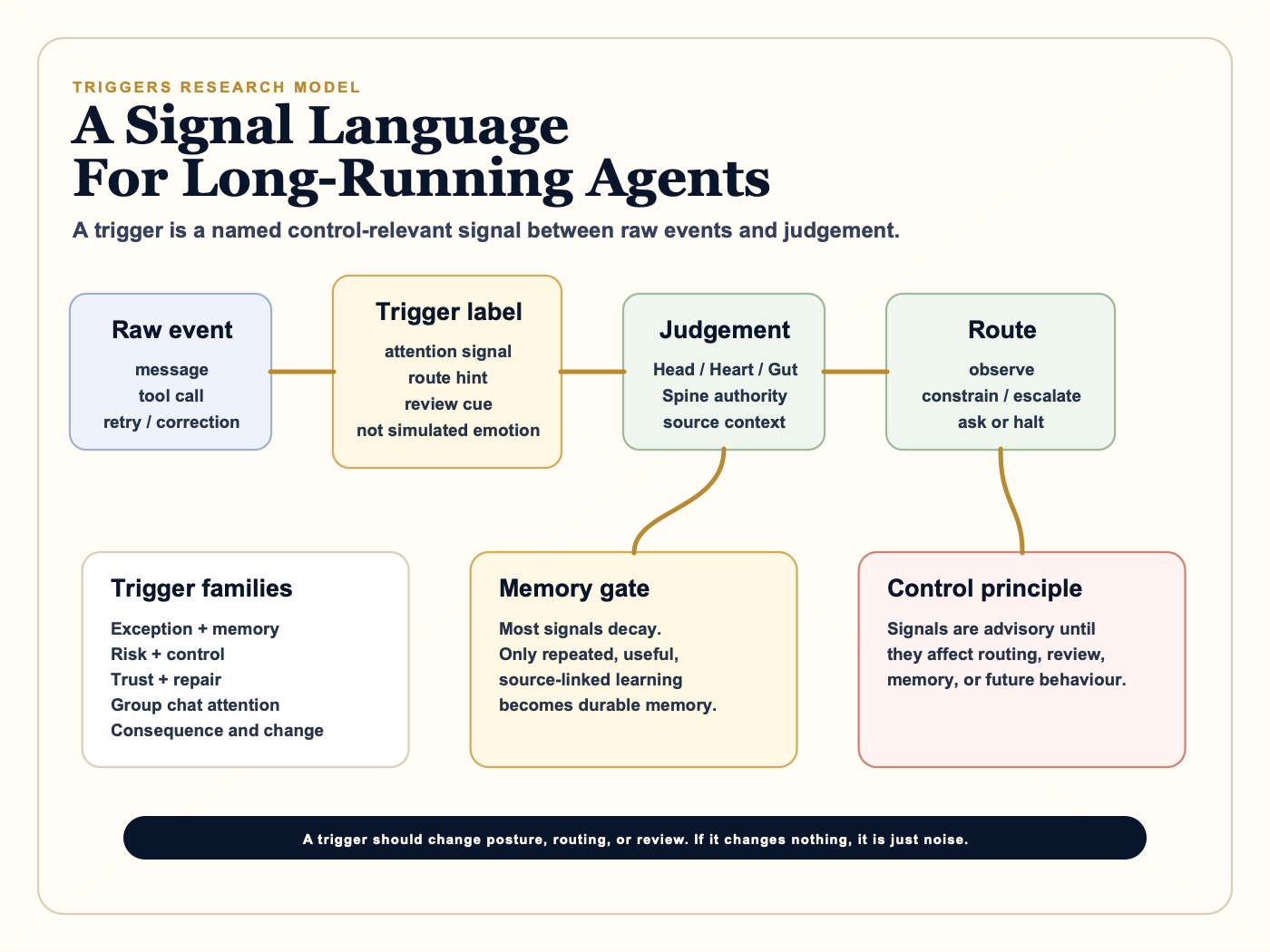
2. What a Trigger Is
A trigger is a named signal that changes routing, interpretation, memory, or review posture.
It is not:
- a simulated emotion;
- a personality trait;
- a justification for action by itself;
- a vague atmosphere attached to text;
- a replacement for security, risk, policy, or human approval.
It is:
- a control-relevant label;
- a reason to inspect, constrain, record, or escalate;
- a human-readable surface over structured metadata;
- an input into judgement.
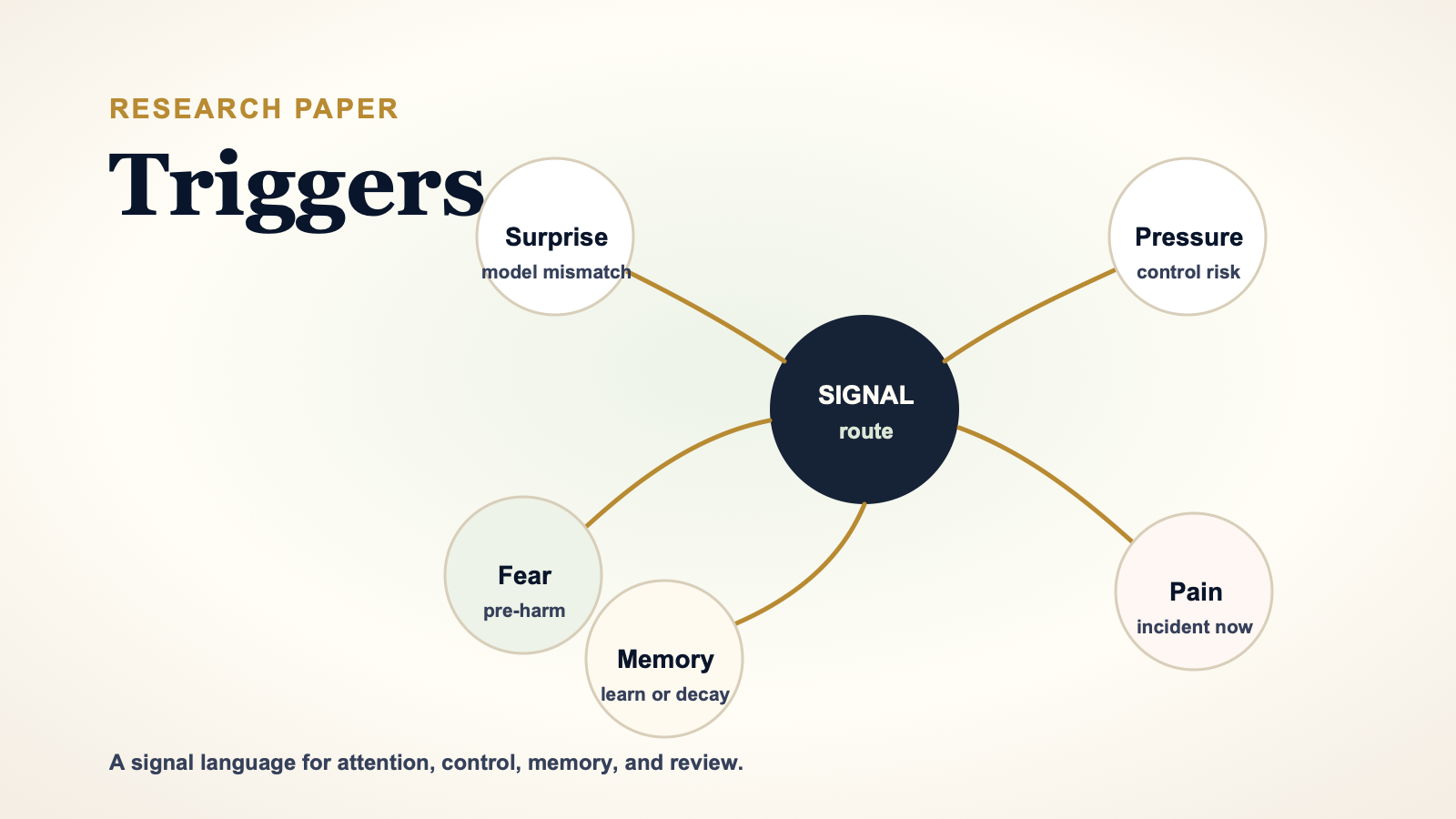
The SNAXK signal notes define this plainly: signals are about state and posture, not personality and identity. That distinction matters. The word "fear" is useful only if it means credible pre-harm warning. "Pain" is useful only if it means active damage or incident pressure. "Surprise" is useful only if it points to model mismatch. Without operational definitions, emotional language becomes theatre.
3. The First Trigger Set
The current trigger language clusters into six families.
3.1 Exception and Memory Triggers
These answer: should this become a memory candidate?
The four public memory triggers are:
- Surprise: the world behaves differently from the expected baseline.
- Shame: a process, judgement, or integrity gap appears where the system should have known or done better.
- Curiosity: something novel or ambiguous deserves bounded exploration.
- Distrust: a source, pattern, counterpart, or route looks risky, deceitful, inconsistent, or off-norm.
The point is not to keep a poetic diary. The point is to generate structured memory objects. A trigger-worthy memory should include:
- trigger type;
- what happened;
- expected baseline;
- impact;
- action taken and outcome;
- whether this is discovery or rediscovery;
- confidence;
- recency;
- tags;
- source links.
This is the move from logging to learning.
3.2 Risk and Control Triggers
These answer: should the system slow down, reduce autonomy, or stop?
The main risk-control triggers are:
- Fear: credible pre-harm warning.
- Pain: active damage, incident, or breach pressure.
- Pressure: urgency or force is degrading judgement.
- Confusion: context is too incoherent to interpret safely.
Fear and pain should be kept separate. Fear says harm may happen if the system continues unchanged. Pain says harm is happening, or incident conditions are strong enough to act as if harm is active.
Pressure and confusion are also essential because many failures begin before there is a clear technical exception. A rushed instruction, an unclear request, a contradiction, or a demand to bypass normal verification can be more important than the surface content of the message.
3.3 Trust and Repair Triggers
These answer: how should trust posture change?
The important signals here are:
- Distrust: reliability has dropped below the autonomy route being assumed.
- Shame: the system may be breaching its own standard.
- Forgiveness: credible repair may justify constructive re-engagement, without restoring trust automatically.
This distinction matters in organisational settings. A system can treat someone civilly while keeping permissions narrow. It can recognise repair without erasing the underlying risk. It can identify its own breach without turning the runtime into blame language.
3.4 Group Chat and Attention Triggers
These answer: should a long-running agent intervene, observe, capture, escalate, or ask for structure?
In high-volume group chat, the worst default is always-on attention. SNAXK's group chat trigger framework uses five practical questions:
- Is this for me?
- Should I engage?
- What is the lowest-cost helpful action?
- Should I capture this?
- Is the channel or thread configured badly enough to ask for better structure?
The trigger families are:
- Addressivity: direct mention, role mention, direct reply, name call-out, explicit question.
- Governance materiality: decision, approval, risk, compliance, reporting, culture, stakeholder trust, owner ambiguity.
- Stall and diffusion: direct question hanging, repeated confusion, no owner, urgency without a decision-maker.
- Capture-worthiness: decision, action, risk signal, near miss, evidence link, reusable lesson.
- Channel hygiene: decision work in a noisy channel, sensitive material in a shared space, no clear distinction between FYI and decision-needed.
The routes are:
- reply;
- observe;
- capture;
- escalate;
- ask for structure.
The key move is restraint. A trigger should not make the agent noisy. It should help the agent be useful with the lowest safe intervention.
3.5 Consequence Triggers
These answer: has the work crossed from conversation into action?
In "When Do We Need Judgement?", the useful threshold is consequence. Many interactions can stay in low-friction conversation or context-gathering mode. Judgement becomes necessary when an action affects people, money, records, commitments, permissions, or reversibility.
Common consequence triggers include:
- spending money;
- contacting someone;
- changing a record;
- interpreting policy;
- acting on behalf of a company;
- making a promise;
- making a public statement;
- making a permanent or hard-to-reverse change;
- making a choice that affects a person;
- accepting a trade-off or permission;
- moving from "could" to "will".
This is one of the most important trigger classes for practical deployment. The system does not need to slow every sentence down with formal governance. It does need to notice when ordinary interaction becomes consequential action.
3.6 Change Triggers
These answer: has the operating policy changed?
Long-lived agents inherit instructions. Over time, those instructions become operational policy. If changes arrive casually, the agent can suffer silent permission drift.
A change note should say:
- what is changing;
- why it is changing;
- what previous instruction it replaces;
- what must stay true;
- which systems, projects, or decisions it affects;
- whether the change is permanent, experimental, or temporary;
- what the agent should challenge before accepting it.
This turns change itself into a trigger for judgement. A refusal or objection from an agent may not be friction. It may be the system remembering a boundary the human has forgotten.

4. Signal Catalogue
The following catalogue gives the public language and operational meaning of the main triggers.
| Signal | Operational meaning | Primary lane | Typical route | What it is not |
|---|---|---|---|---|
| Fear | Credible pre-harm warning | Gut, then Head and Heart | Observe, constrain, limp, stop, escalate | Panic |
| Surprise | Model mismatch | Head | Verify, lower confidence, create memory candidate | Excitement for novelty |
| Pain | Active damage or incident pressure | Gut and Spine | Halt, degrade, preserve context, escalate | Ordinary inconvenience |
| Distrust | Reliability drop | Gut and Heart | Reduce autonomy, narrow disclosure, increase checks | Dislike |
| Shame | Internal standard breach warning | Heart and Spine | Repair, tighten controls, review | Humiliation |
| Forgiveness | Constructive stance after credible repair | Heart, bounded by Gut and Spine | Re-engage carefully, keep trust separate | Automatic trust restoration |
| Pressure | Haste is becoming a control risk | Gut and Head | Slow down, verify, smallest safe step | Productivity |
| Confusion | Not enough coherent model fit to act safely | Head | Clarify, refuse speculation, lower confidence | Curiosity |
| Curiosity | Bounded exploration pressure | Head, usually in reflection | Investigate in low-risk mode | Permission for live risky action |
Some combinations matter more than single signals:
- Surprise + pressure: the model does not fit reality, and urgency is trying to force a fast answer. Verify first.
- Fear + weak localisation: harm is plausible, but the blast radius is unclear. Degrade or escalate.
- Pain + high confidence: treat as incident posture. Halt or limp, preserve context, escalate.
- Distrust + shame: the outside source is unreliable and the planned response may breach the system's own standard. Tighten hard.
5. Fear: The Pre-Harm Signal
Fear is the clearest example of why the emotional word is useful only when disciplined.
In a human, fear can be messy, embodied, social, and sometimes wrong. In an agentic system, fear should mean one thing: if we continue unchanged, harm may happen.
Useful dimensions are:
- severity;
- confidence;
- localisation;
- horizon;
- type.
Types may include:
- safety or ethics;
- data or privacy;
- financial or operational risk;
- trust or reputation;
- strategic drift.
The response ladder should be explicit:
- Observe: keep watch, gather more evidence.
- Constrain: reduce autonomy, narrow scope, add checks.
- Limp: continue in degraded protective mode.
- Stop the line: halt the path that may cause harm.
- Escalate: ask for explicit or dual approval.
Fear fails when it becomes too quiet, too loud, too theatrical, or permanent:
- fear suppression ignores weak signals until pain appears;
- fear inflation makes everything seem dangerous;
- fear theatre produces dramatic labels with no routing consequence;
- fear lock-in keeps a system constrained long after the risk has cleared.
The practical test is whether fear changes the response posture in a reviewable way.
6. Pain: Sharp Incidents, Dull Aches, and Limp Mode
The pain metaphor is powerful because pain routes attention and changes behaviour. The MedlinePlus definition of pain as a nervous-system signal that something may be wrong is useful here, not as a medical claim, but as an engineering pattern.
In agentic systems:
- sharp pain maps to incident now;
- dull ache maps to persistent issue;
- limp mode maps to deliberate protective behaviour while the ache persists.
A sharp pain signal should usually:
- detect failure or boundary breach;
- emit a signal with context;
- route to incident management;
- contain impact;
- communicate plainly to humans;
- preserve context for later learning.
A dull ache signal should usually:
- identify persistent risk;
- reduce automation on the affected path;
- add verification;
- slow the rate of change;
- increase sampling;
- route more approvals to humans;
- avoid the shaky route until confidence improves.
This connects agentic design to established incident and reliability practice. Google SRE's incident management work emphasises limiting disruption and restoring operations quickly. Observability practice, as framed by OpenTelemetry, emphasises understanding a system from the outside through useful signals. The trigger model borrows from both, but adds a human-readable routing layer for agents and operators.
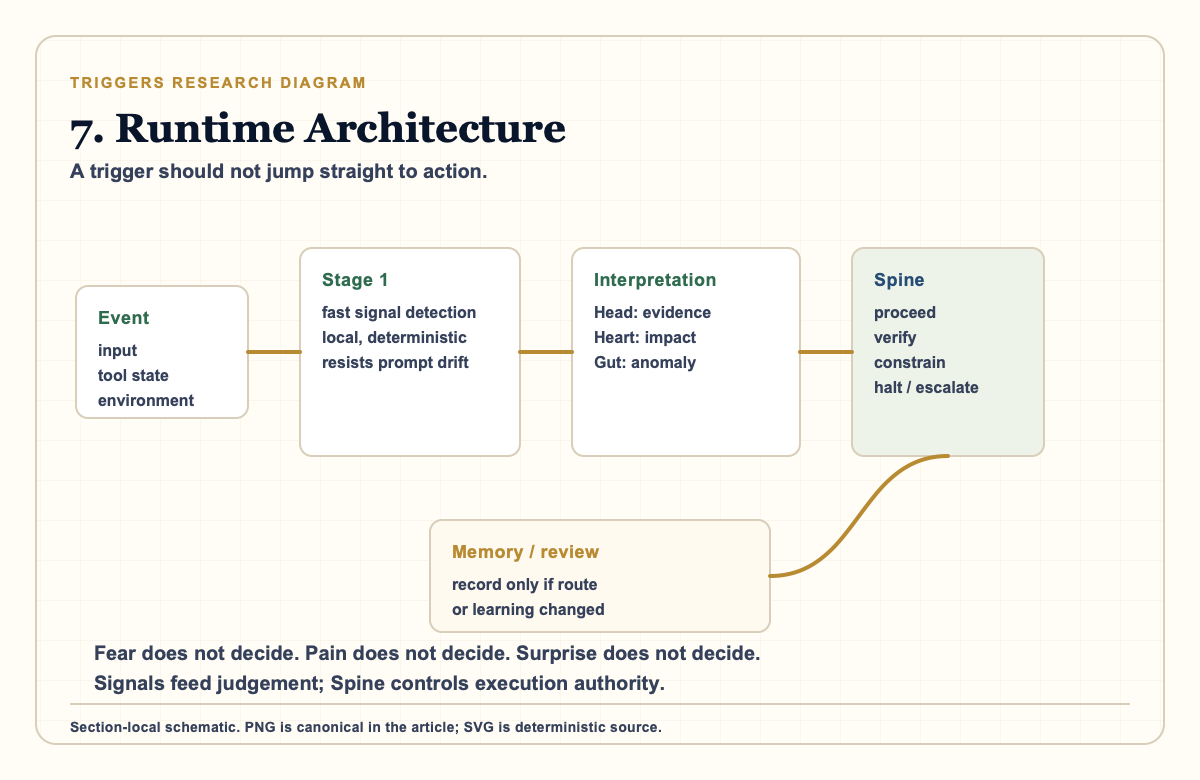
7. Runtime Architecture: From Signal to Judgement
A trigger should not jump straight to action. The safer shape is:
event
-> Stage 1 signal detection
-> Head / Heart / Gut interpretation
-> Spine decision
-> route, memory, review, or actionStage 1 should be fast, local, deterministic where possible, and resistant to prompt-level manipulation. It can detect simple patterns: pressure, distrust, anomaly, surprise, hard-stop shape, repeated failure, source mismatch, or consequence threshold.
Stage 2 can be slower and more interpretive. It asks what the signal means in context. This is where Head, Heart, and Gut become useful:
- Head asks whether the evidence is strong enough.
- Heart asks what this will do to people and trust.
- Gut asks what feels off before damage lands.
Spine then decides what is allowed:
- proceed;
- verify;
- ask one clarifying question;
- constrain;
- limp;
- refuse;
- stop;
- escalate.
This prevents the trigger language from becoming a set of magic buttons. Fear does not decide. Pain does not decide. Surprise does not decide. They feed the judgement system.
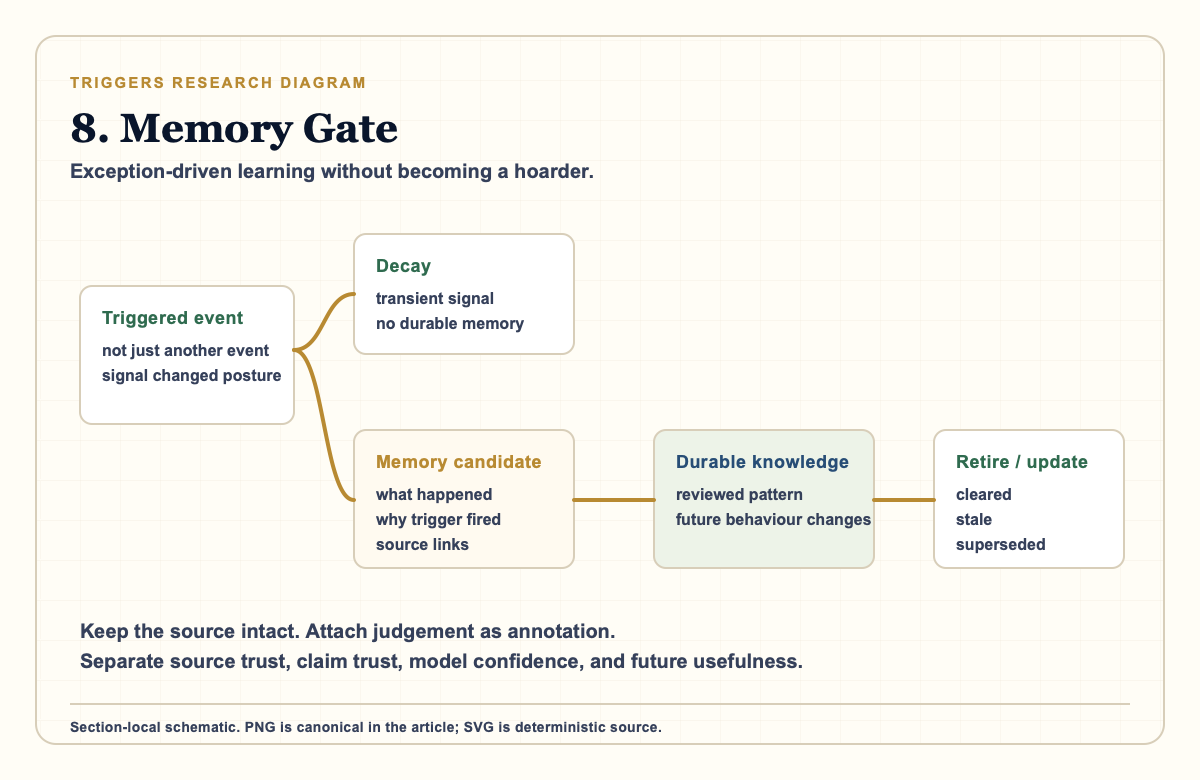
8. Memory: Triggers as the Gate Between Noise and Learning
The most important memory rule is that not every triggered event should become durable memory. Some signals are transient and should decay. Others should become structured memory candidates. A smaller subset should become durable organisational knowledge.
A good memory candidate answers:
- What happened?
- What did we expect?
- Why did the trigger fire?
- What changed because of it?
- Did the action help?
- Is this new discovery or rediscovery of a known pattern?
- What source supports this?
- What would clear, update, or retire the memory later?
Source-linked memory matters. The agent should preserve the original source and attach judgement as annotation, not overwrite the source with a summary that later becomes unchallengeable. This aligns with broader web standards work on annotations and provenance: keep the thing, then attach interpretable claims about the thing.
The SNAXK memory language separates:
- source trust;
- claim trust;
- model confidence;
- affective or signal posture;
- usefulness later;
- whether source reopening was needed.
That separation is what makes memory auditable rather than mystical.
9. Human Persuasion Triggers vs Agent Inspection Triggers
One reason the trigger language matters is that human and agentic attention do not operate the same way.
Human marketing and persuasion often work through:
- attention;
- desire;
- aspiration;
- familiarity;
- scarcity;
- social proof;
- story;
- status;
- identity;
- trust;
- reassurance;
- habit;
- taste;
- theatre.
Agents should not be persuaded by these in the same way. They should inspect:
- evidence;
- fit;
- constraints;
- cost;
- failure modes;
- provenance;
- trustworthiness;
- approval requirements;
- reversibility.
This suggests future systems may need dual surfaces. One surface may be legible and motivating for humans. The other must be inspectable by agents. A slogan can move a person; an agent needs claims, evidence, constraints, and a route.
10. Evaluation and Failure Modes
Trigger systems can fail. The main failure modes are predictable.
Trigger spam
If everything is interesting, nothing is. Trigger spam recreates the memory-hoarding problem under a more sophisticated name.
Mitigation:
- thresholds;
- decay;
- similarity checks;
- baseline tolerances;
- review of which signals actually changed routing.
Shame misuse
Shame is useful only as an internal standard breach warning. If it becomes blame language, it will corrode culture and make review less honest.
Mitigation:
- store process gap, not personal humiliation;
- attach evidence;
- include repair path;
- separate human accountability from system posture.
Paranoia
If distrust fires too easily, the system becomes unusable.
Mitigation:
- require evidence or pattern;
- distinguish unknown from untrusted;
- give trust a path to improve;
- avoid widening permissions automatically after a single positive interaction.
Trivial surprise
Novelty is not importance. Many surprises are harmless.
Mitigation:
- compare against operational baseline;
- require impact or learning value;
- let harmless surprises decay.
Fear theatre
Fear language can become dramatic without being operational.
Mitigation:
- require severity, confidence, localisation, and route;
- define what clears or escalates fear;
- audit whether fear changed behaviour appropriately.
Silent permission drift
Long-lived agents can absorb new instructions without noticing that authority changed.
Mitigation:
- treat change as a trigger;
- require change notes;
- distinguish permanent, experimental, and temporary changes;
- preserve previous boundary references.
11. A Practical Starter Experiment
A team can test this model without rebuilding its entire stack.
- Pick one operational domain: customer operations, governance chat, incident handling, procurement, board papers, or internal knowledge work.
- Define ten triggers from the catalogue.
- For each trigger, write the plain-language meaning and the machine-readable route.
- Attach minimal metadata: intensity, confidence, why it fired, route, owner, what clears it.
- Decide which triggers can create memory candidates.
- Run a one-week review.
- Count false positives, false negatives, useful captures, unnecessary interruptions, and prevented mistakes.
- Retire or tighten weak triggers.
- Promote only the useful patterns into durable memory.
The goal is not to make the agent dramatic. The goal is to make it quieter, safer, and more capable of learning.
12. Conclusion
Triggers give long-running agents a practical language for attention, control, memory, and review.
They work because they sit between raw events and formal judgement. They are softer than policy, but more structured than vibes. They are understandable to humans, but useful to machines. They let a system say: this surprised me; this looks unsafe; this is active damage; this is pressure; this is a consequence threshold; this belongs in memory.
Used well, triggers reduce noise. They make agents more inspectable. They create a shared language between operators, leaders, and systems. Most importantly, they help agentic systems learn from exceptions without becoming data hoarders.
The next design challenge is not to invent more trigger words. It is to prove which ones improve decisions, reduce repeated mistakes, and make long-running systems easier to supervise.
References
- Tony Wood, "Don't Build a Hoarder-Build a Learner: Exception-Driven Memory for Agentic AI", 2026.
- Tony Wood, "Pain Signals for Agentic Systems, sharp pain, dull ache, and the operational limp", 2026.
- MedlinePlus, "Pain", National Library of Medicine.
- Google SRE Book, "Managing Incidents".
- OpenTelemetry, "Observability primer".
- CloudEvents, "CloudEvents".
- W3C, "Web Annotation Data Model".
- W3C, "PROV-Overview".